|
1
|
- Il disegno della ricerca sociale ed elementi di statistica inferenziale
- Prof. Renato Grimaldi
- Con la collaborazione di Mariella Piscopo e Adelaide Gallina
- Elaborazione multimediale a cura di Anna De Luca
|
|
2
|
- 0. Premessa
- 1. Analisi Monovariata: aspetti teorici
- 2. Analisi monovariata: aspetti computazionali
- 3. Le rappresentazioni grafiche
- 4.Teoria e ipotesi
- 5. Il disegno della ricerca
- 6. La distribuzione normale
- 7. La stima intervallare
- 8. La numerosità campionaria
- 9. Analisi bivariata: tabella a doppia entrata
- 10. Analisi bivariata: analisi della varianza
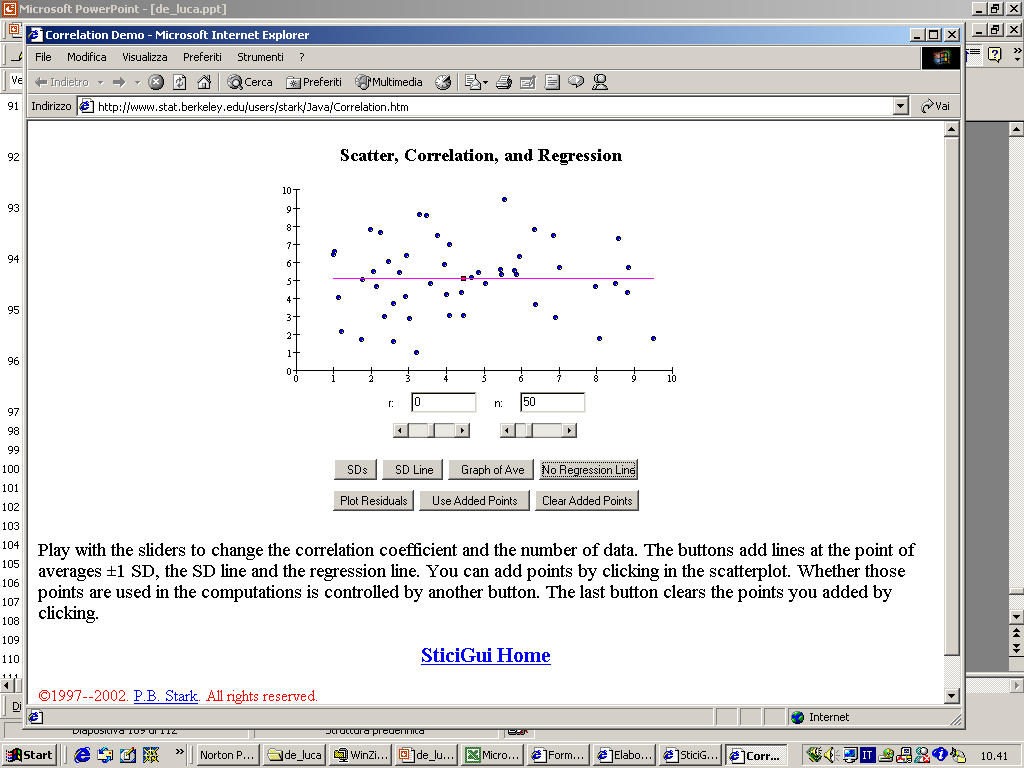
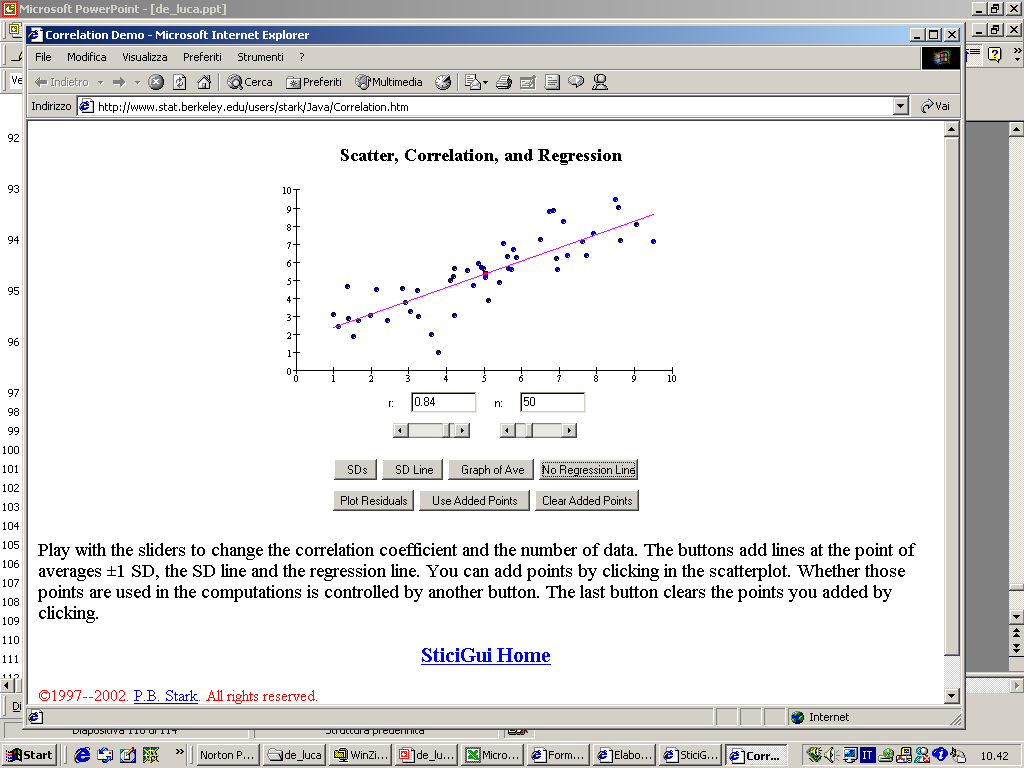
- 11. Analisi bivariata: la correlazione
- 12: Analisi bivariata: la regressione
- 13. Glossario
- 14. Bibliografia
|
|
3
|
- Il corso on-line di Metodologia e Tecnica della Ricerca Sociale si pone
l’obiettivo di aiutare lo studente a comprendere alcuni concetti
rilevanti per l’analisi dei dati, attraverso l’uso di Internet. La rete
possiede numerosi laboratori virtuali interattivi, che facilitano
l’acquisizione di alcuni concetti chiave, mediante simulazioni che
consentono di far emergere la costruzione della teoria. In merito alla
stima statistica ne abbiamo selezionati alcuni e inseriti nel corso, in
tal modo lo studente può lavorare, attivando una videata parallela a
quella qui proposta, sperimentando gli esercizi direttamente nel
laboratorio virtuale.
|
|
4
|
- Usufruendo del corso on-line, per attivare pagine web in un’altra
finestra, oltre a quella del corso, ed avere quindi contemporaneamente
entrambe le applicazioni attive è necessario selezionare l’indirizzo web
del sito indicato, cliccarvi sopra premendo contemporaneamente il tasto shift
della tastiera. In tal modo sarà possibile all’utente lavorare nel
laboratorio attivato senza perdere la videata power point del corso
on-line.
|
|
5
|
|
|
6
|
|
|
7
|
|
|
8
|
|
|
9
|
|
|
10
|
|
|
11
|
|
|
12
|
|
|
13
|
|
|
14
|
|
|
15
|
|
|
16
|
|
|
17
|
|
|
18
|
|
|
19
|
|
|
20
|
|
|
21
|
|
|
22
|
|
|
23
|
|
|
24
|
|
|
25
|
|
|
26
|
|
|
27
|
|
|
28
|
|
|
29
|
|
|
30
|
|
|
31
|
|
|
32
|
|
|
33
|
|
|
34
|
|
|
35
|
|
|
36
|
|
|
37
|
|
|
38
|
|
|
39
|
|
|
40
|
|
|
41
|
|
|
42
|
|
|
43
|
|
|
44
|
|
|
45
|
|
|
46
|
|
|
47
|
|
|
48
|
|
|
49
|
|
|
50
|
|
|
51
|
|
|
52
|
|
|
53
|
|
|
54
|
|
|
55
|
|
|
56
|
|
|
57
|
|
|
58
|
|
|
59
|
|
|
60
|
|
|
61
|
|
|
62
|
|
|
63
|
|
|
64
|
|
|
65
|
|
|
66
|
|
|
67
|
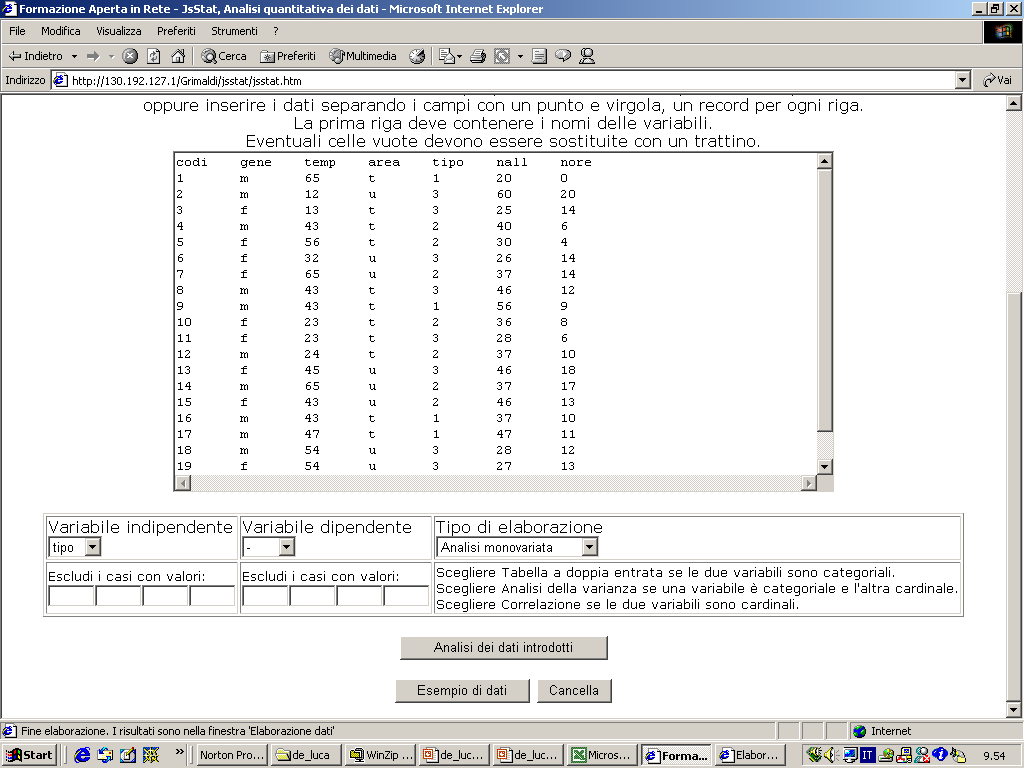
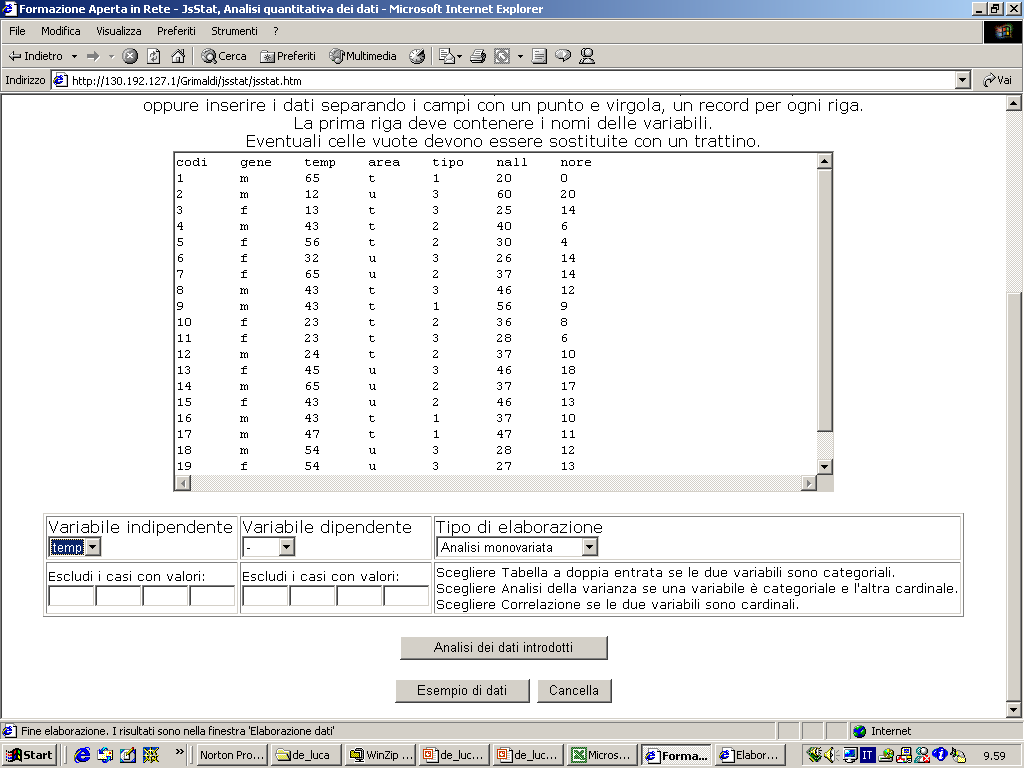
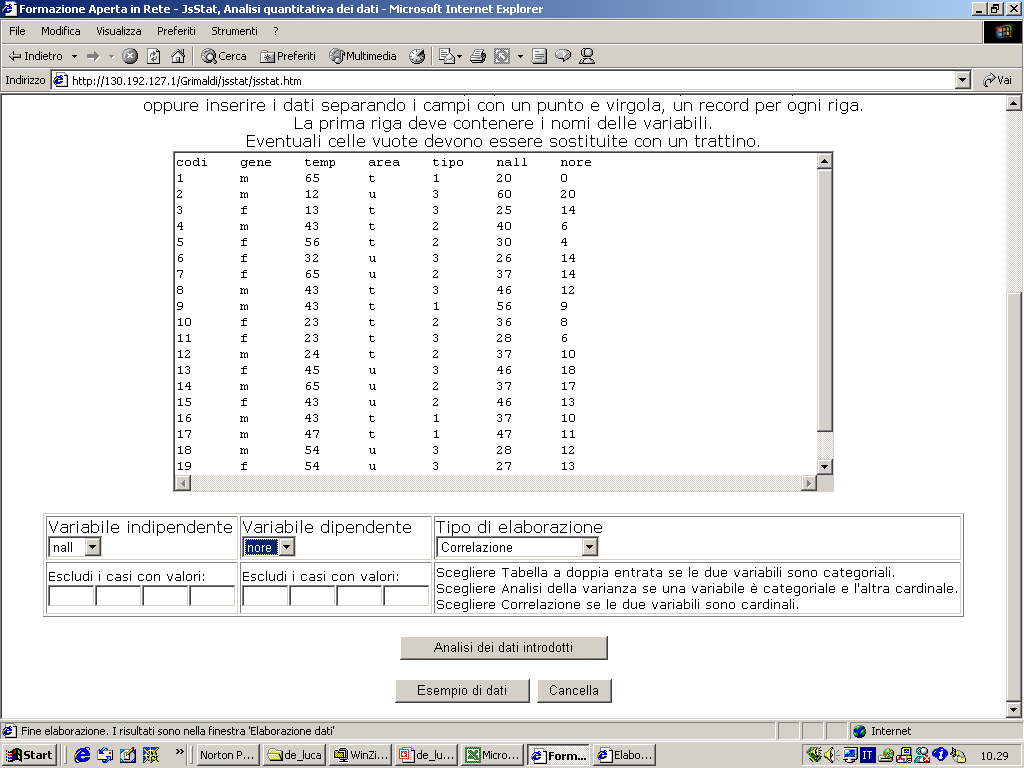
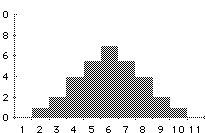
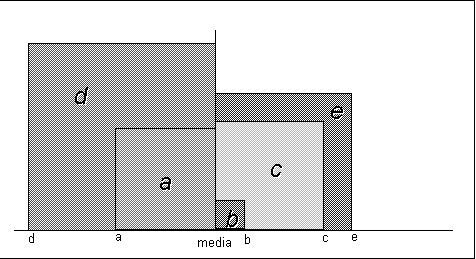
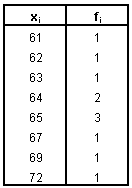
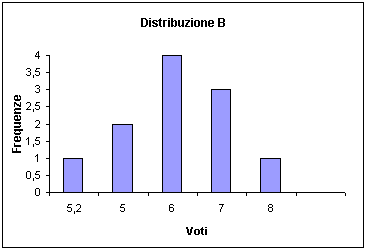
- Si ricorre a questo tipo di rappresentazione quando si lavora con
variabili cardinali (es: l’età o il voto di maturità come nella figura).
- L’istogramma si costruisce partendo da una tabella di frequenza.
- L’asse delle ascisse riporta i valori della variabile considerata (con
il livello di scala almeno ad intervalli).
|
|
68
|
|
|
69
|
- Il box plot è utilizzato per fornire una rappresentazione grafica
dell’analisi esplorativa della
distribuzione di una variabile almeno categoriale ordinata.
|
|
70
|
|
|
71
|
|
|
72
|
|
|
73
|
|
|
74
|
|
|
75
|
|
|
76
|
- Teorie e ipotesi sono le forme di asserto più usate nella scienza.
- Per asserto si intende una costruzione mentale passibile di essere
pensata come vera o falsa.
- Gli studenti del corso di laurea in scienze dell’educazione è un concetto,
anche se formato di più termini, e non un asserto.
- Gli studenti del corso di laurea in scienze dell’educazione sono
prevalentemente di genere femminile è un asserto. Esso asserisce infatti
qualcosa che può essere pensato o controllato come vero o falso (Grimaldi,
2000, cap. 3)
|
|
77
|
|
|
78
|
|
|
79
|
|
|
80
|
|
|
81
|
|
|
82
|
- Le fasi fondamentali della ricerca
|
|
83
|
|
|
84
|
- In questa fase il ricercatore sceglie il problema e formula la teoria
e le ipotesi della ricerca.
- In un’indagine sugli studenti di Scienze dell’Educazione la teoria
potrebbe affermare che l’utilizzo delle strutture didattiche da parte
degli studenti ne migliora il
successo universitario e l’ipotesi potrebbe affermare che esiste una
relazione positiva tra frequenza alle lezioni e risultati, ossia che la
frequenza (misurata come numero di ore settimanali di frequenza ai
corsi) tende ad influenzare positivamente la media dei voti degli esami
sostenuti.
|
|
85
|
|
|
86
|
|
|
87
|
|
|
88
|
|
|
89
|
|
|
90
|
|
|
91
|
|
|
92
|
|
|
93
|
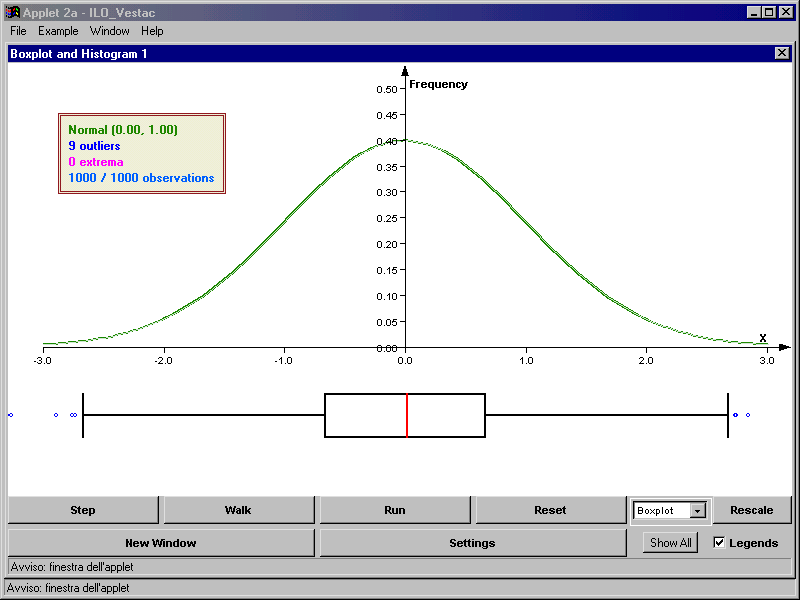
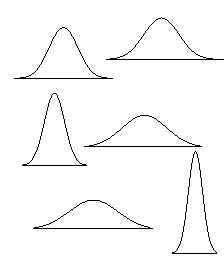
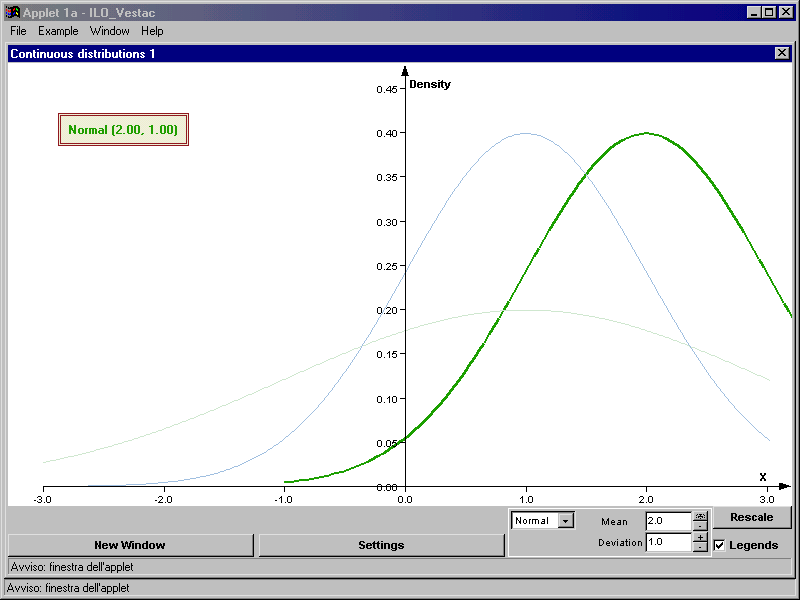
- Una distribuzione normale assume una tipica forma a campana, simmetrica
all’asse verticale.
- Negli esempi riportati si può notare come le curve possano assumere dei
profili diversi anche avendo la stessa area.
|
|
94
|
|
|
95
|
|
|
96
|
|
|
97
|
|
|
98
|
|
|
99
|
|
|
100
|
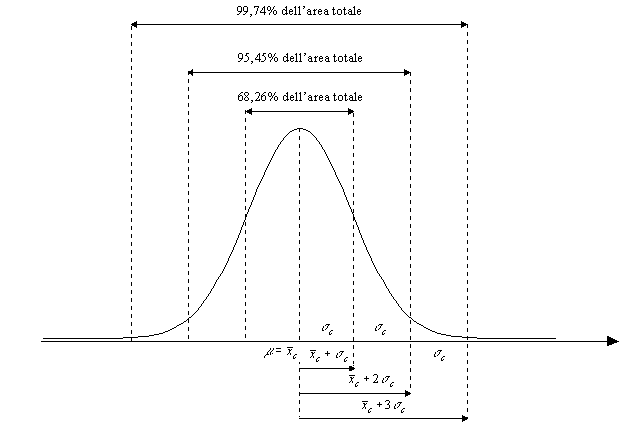
- La distribuzione normale standardizzata è particolarmente utile nelle
operazioni di stima statistica e per comparare tra loro valori
provenienti da differenti distribuzioni, anche non normali (ad esempio
per comparare il voto di italiano di uno studente proveniente dalla
scuola A con quello nella stessa materia di un altro studente
proveniente dalla scuola B).
- Essa presenta media uguale a 0 e scarto tipo pari a 1.
|
|
101
|
|
|
102
|
|
|
103
|
|
|
104
|
|
|
105
|
|
|
106
|
|
|
107
|
|
|
108
|
|
|
109
|
|
|
110
|
|
|
111
|
|
|
112
|
|
|
113
|
|
|
114
|
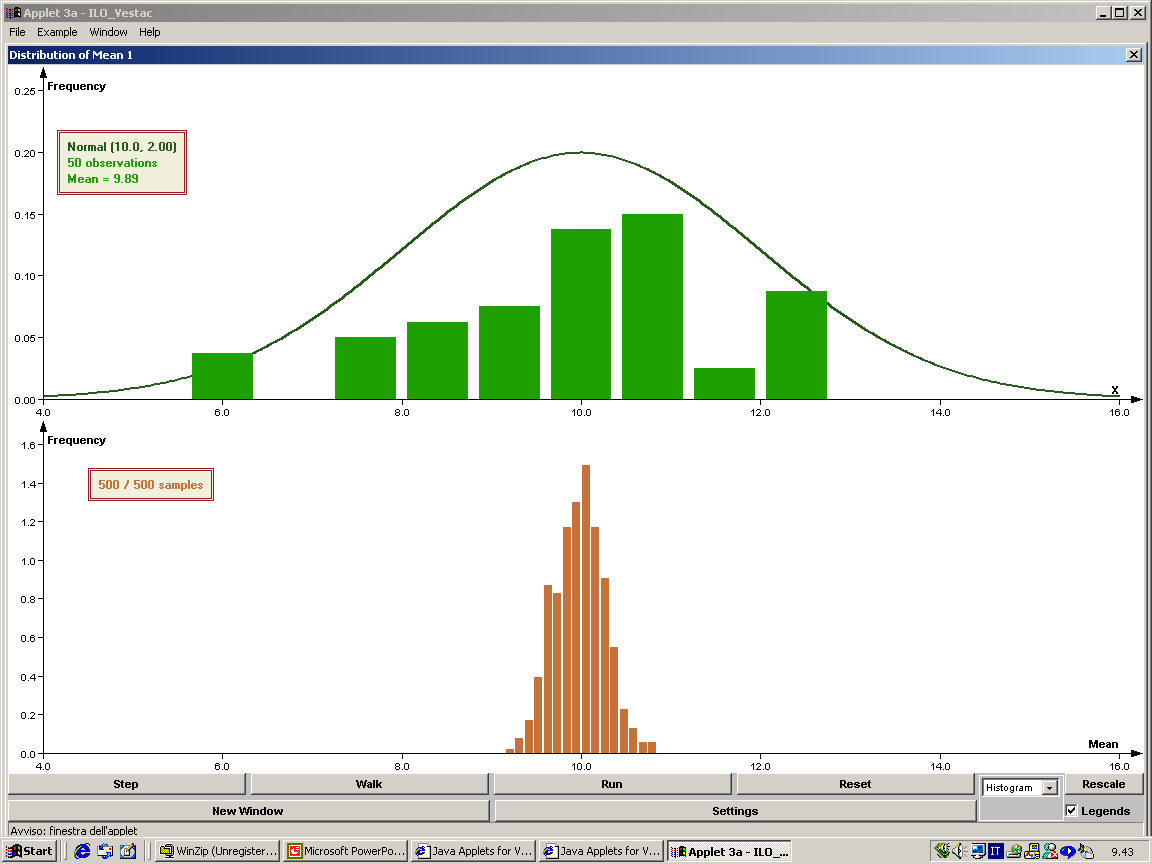
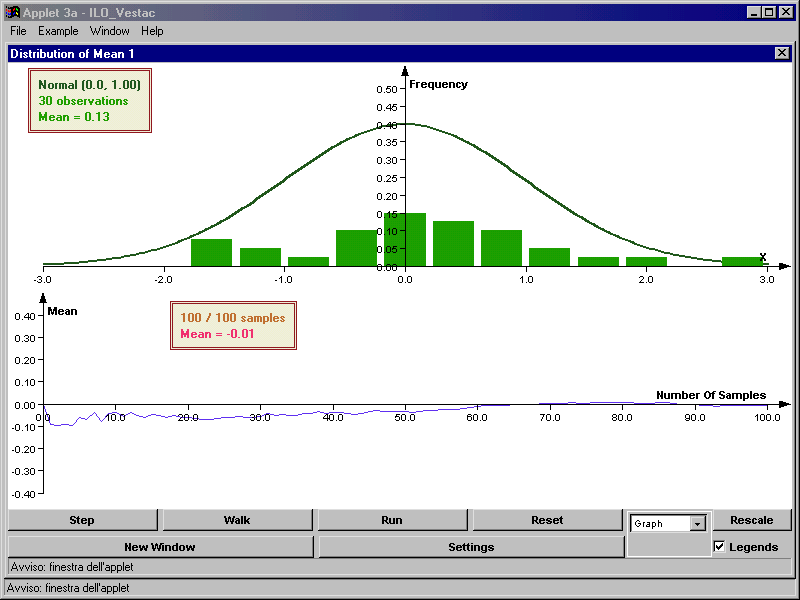
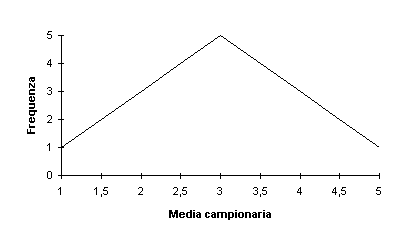
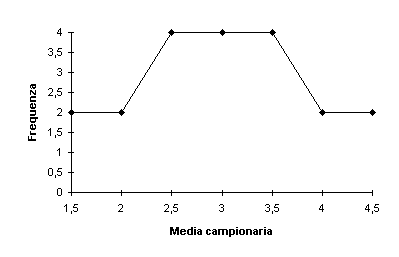
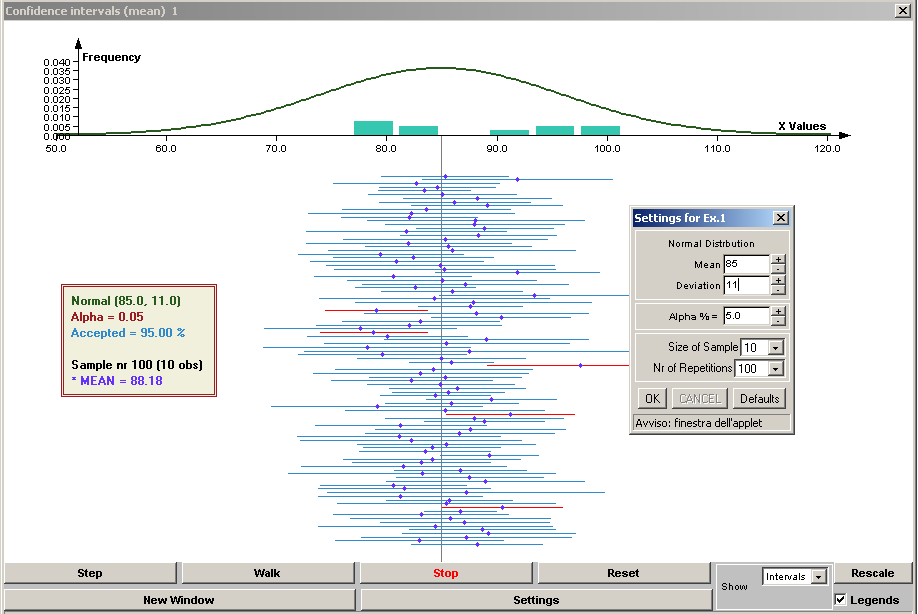
- La distribuzione delle medie campionarie segue il teorema del limite
centrale anche se la popolazione di partenza non è normale quando il
campione è elevato, approssimativamente superiore alle 30 unità. Di
seguito si portano due esempi al riguardo, sia con estrazione con
reimmissione sia senza reimmissione. I realtà per fare l’esperimento la
popolazione è piccola (5 casi) e il campione ancor di più (2 casi).
Questo esempio serve a farci capire che la media di tutte le medie dei
campioni corrisponde alla media e che anche per piccoli campioni la
distribuzione delle medie campionarie tende ad assomigliare alla normale
(anche per piccoli campioni).
|
|
115
|
|
|
116
|
|
|
117
|
|
|
118
|
|
|
119
|
|
|
120
|
|
|
121
|
|
|
122
|
|
|
123
|
|
|
124
|
|
|
125
|
|
|
126
|
|
|
127
|
|
|
128
|
|
|
129
|
|
|
130
|
|
|
131
|
|
|
132
|
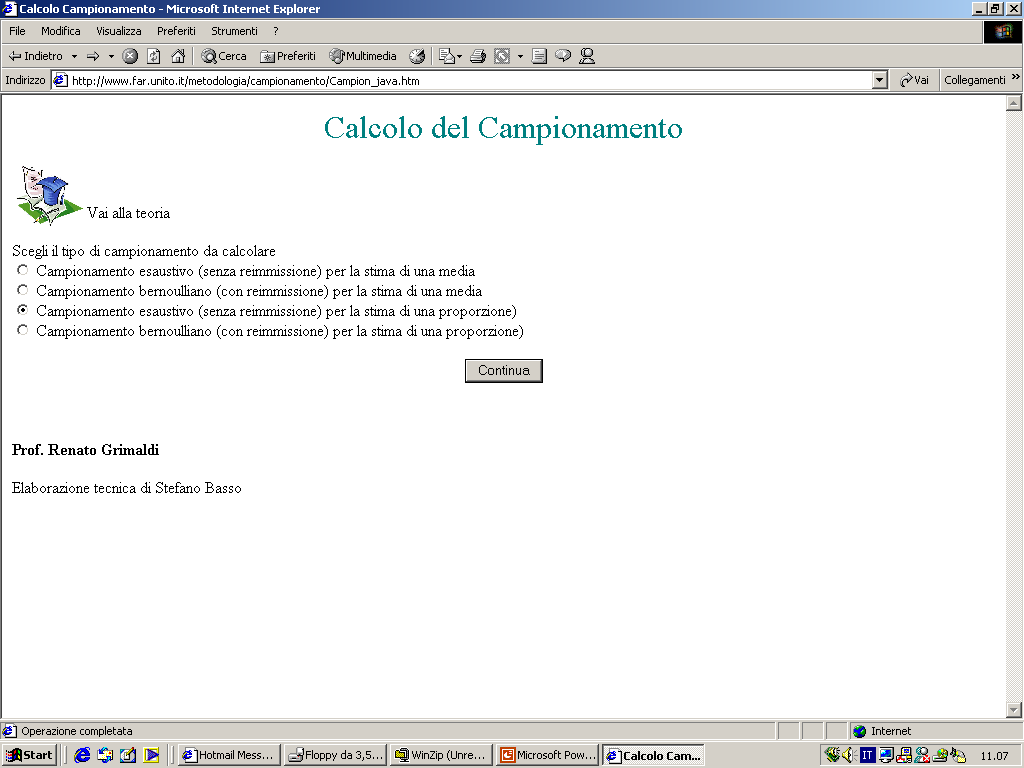
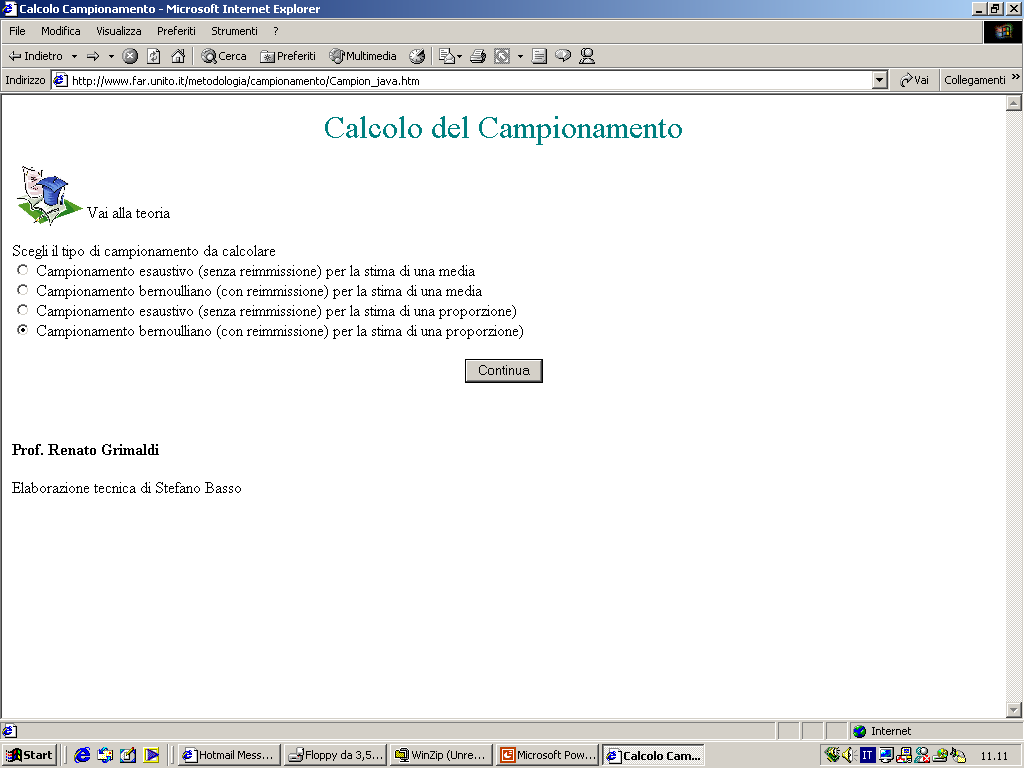
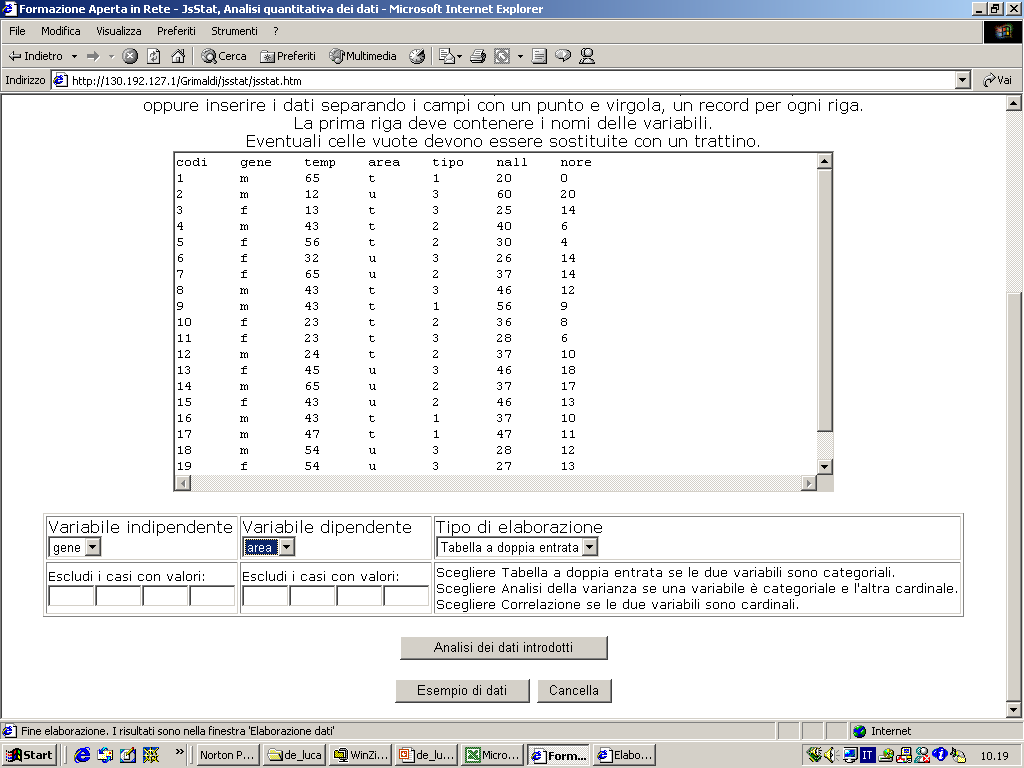
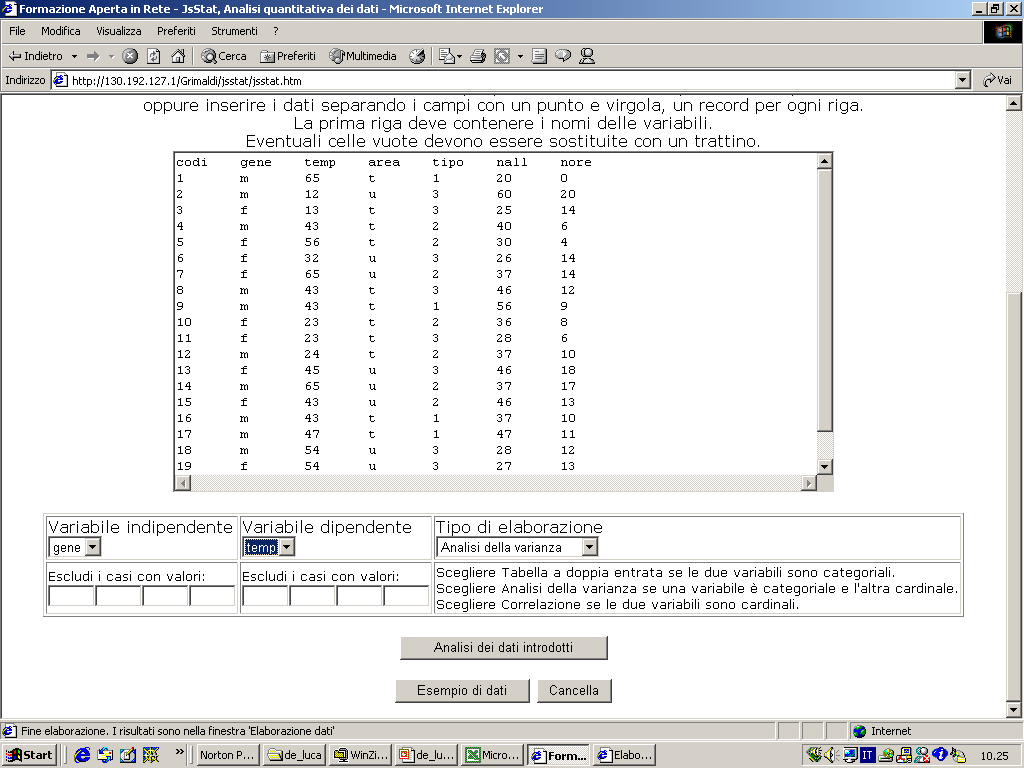
- Gli statistici hanno elaborato delle tecniche a seconda del grado di
conoscenza della realtà che si vuole investigare. La tabella che segue
ci aiuta ad orientarci nella casistica che si viene a determinare.
- In merito al parametro numerosità campionaria, occorre dire che di
solito si considerano piccoli campioni quelli che hanno
approssimativamente meno di 30 casi, medio-grandi i campioni con più di
30 casi.
|
|
133
|
|
|
134
|
|
|
135
|
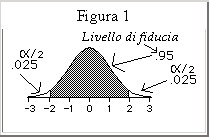
- La formula per calcolare gli intervalli di fiducia è la seguente:
- dove dipende dal livello di
significatività prescelto.
- Esempio: si estrae un campione di 15 unità da una popolazione di
soggetti residenti nella valle d’Aosta. Si vuole calcolare l’intervallo
di fiducia che con una probabilità nota e prescelta contiene il
parametro vero e sconosciuto della popolazione. Il reddito medio del
campione è pari a 2000
€, lo scarto tipo della popolazione
=200 €. Scelto il livello di significatività =0.05, l’intervallo sarà:
- Svolgendo i calcoli otterremo che la media della popolazione, sarà
compresa con una probabilità del 95% nell’intervallo:
- 1769< < 2231
|
|
136
|
-
3. Lo scarto tipo (deviazione standard) della popolazione è noto,
il campione ha numerosità qualsiasi (< o > di 30 casi) e la forma
può essere o meno normale
- Quando lo scarto tipo della
popolazione è noto (si tratta per lo più di una caso teorico, dato che
di solito quando si conosce lo scarto tipo della popolazione se ne
conosce anche la media), sia che si conosca la forma della distribuzione
della variabile nella popolazione, sia che non la si conosca, la formula
per calcolare gli intervalli di fiducia non cambia ed è pari a:
|
|
137
|
|
|
138
|
|
|
139
|
|
|
140
|
|
|
141
|
|
|
142
|
- L’home page del programma è la seguente:
|
|
143
|
|
|
144
|
|
|
145
|
|
|
146
|
|
|
147
|
|
|
148
|
|
|
149
|
|
|
150
|
|
|
151
|
|
|
152
|
|
|
153
|
|
|
154
|
|
|
155
|
|
|
156
|
|
|
157
|
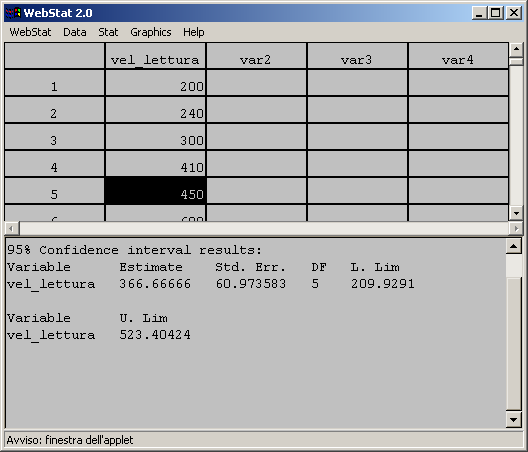
- Applicando la formula [ ]
otteniamo il limite inferiore: LI= 209.904 e il limite superiore: LS =
523.430.
L'intervallo di fiducia al livello del 95% (livello di significatività
di 0.05) sarà:
- Il ricercatore quindi può affermare che, con una probabilità del 95%,
la velocità media di lettura degli alunni, fra cui è stato estratto il
campione, è compresa tra 209.904 e 523.430 parole al minuto.
|
|
158
|
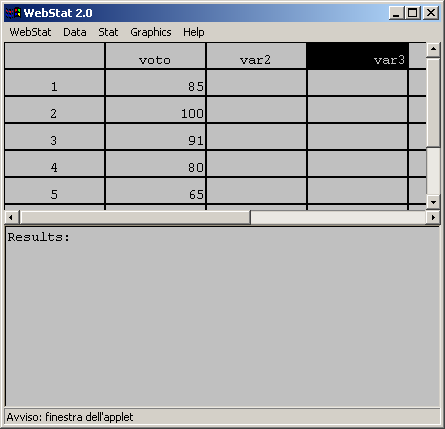
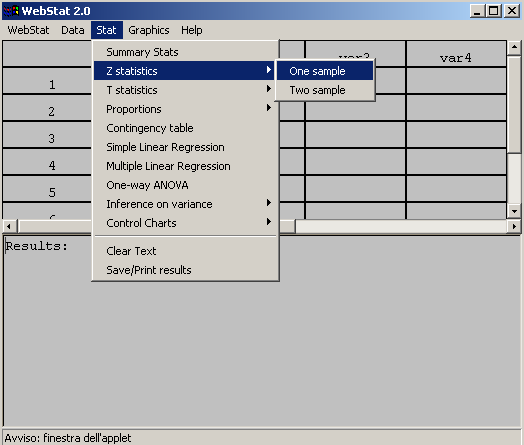
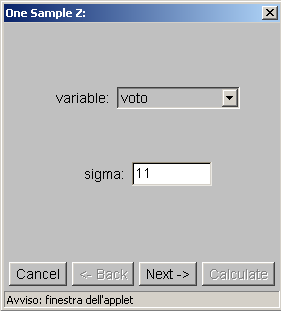
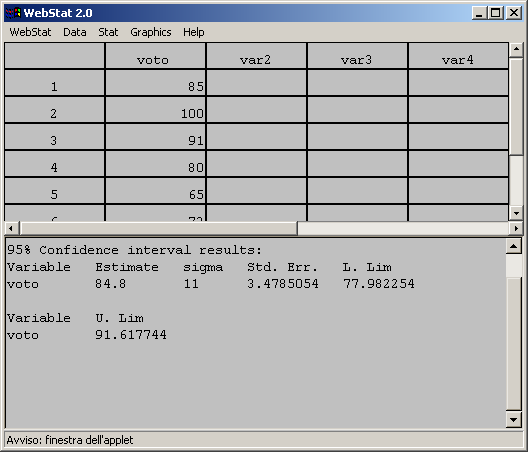
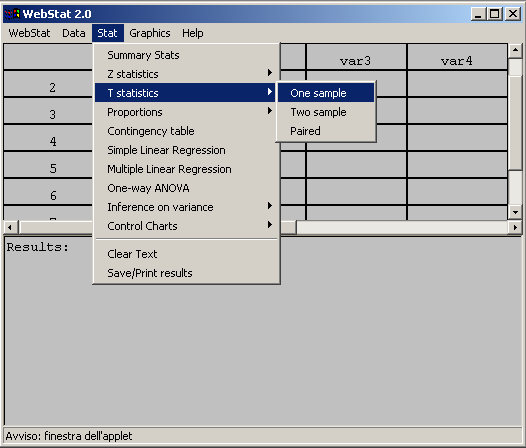
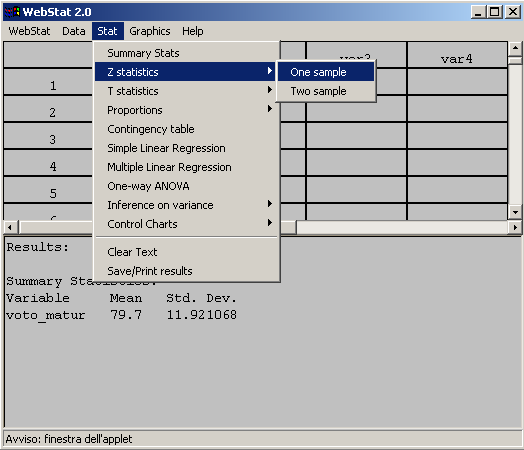
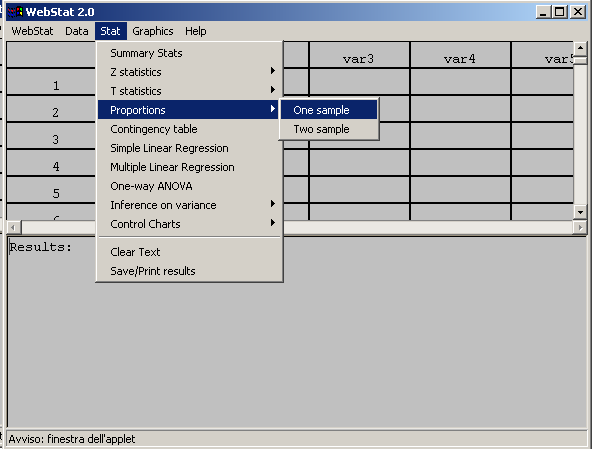
- Con l’ausilio del programma Webstat possiamo calcolare gli intervalli
di fiducia per la media:
|
|
159
|
|
|
160
|
|
|
161
|
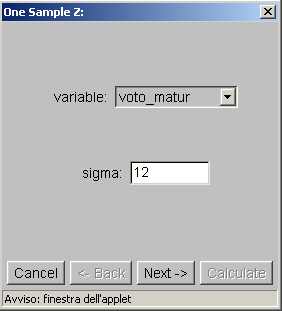
- Un ricercatore è interessato a stimare l’intervallo di fiducia della
media dei voti ottenuti all’esame di maturità dagli studenti che si
iscrivono al corso di laurea in Scienze dell’ Educazione, con un livello
di fiducia del 99%. Estrae casualmente un campione di 60 studenti, ne
calcola la media e lo scarto tipo (deviazione standard). Le informazioni
necessarie sono:
|
|
162
|
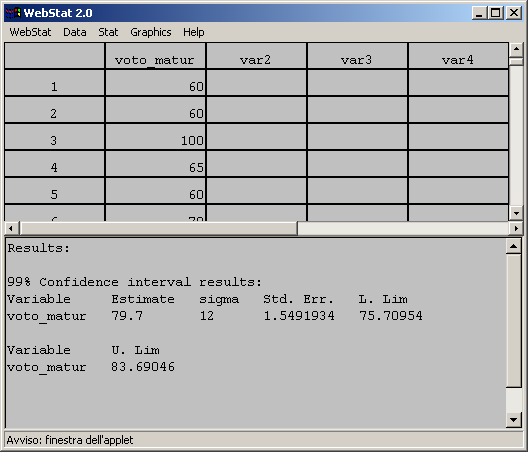
- Applicando la formula
- otteniamo il limite inferiore LI= 76 e il limite superiore LS = 84
- L'intervallo di fiducia ad un livello di attendibilità del 99% (livello
di errore del 0.01) sarà dunque:
- La media dei voti della popolazione da cui il campione è stato estratto
sarà compresa, con una probabilità del 99%, nell’intervallo sopra considerato.
|
|
163
|
|
|
164
|
|
|
165
|
|
|
166
|
|
|
167
|
|
|
168
|
|
|
169
|
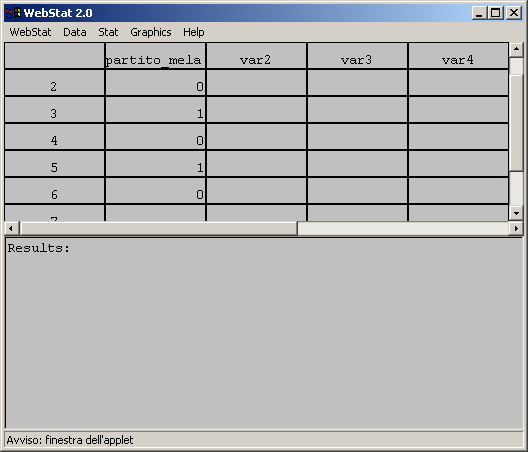
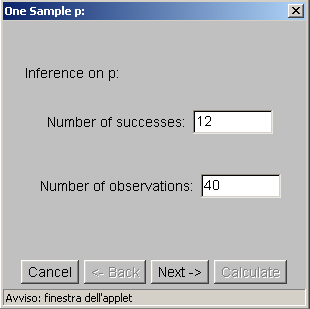
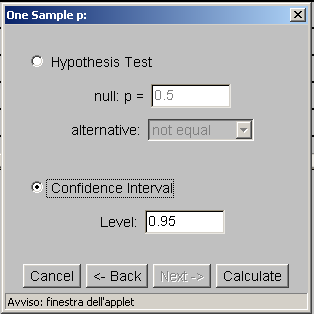
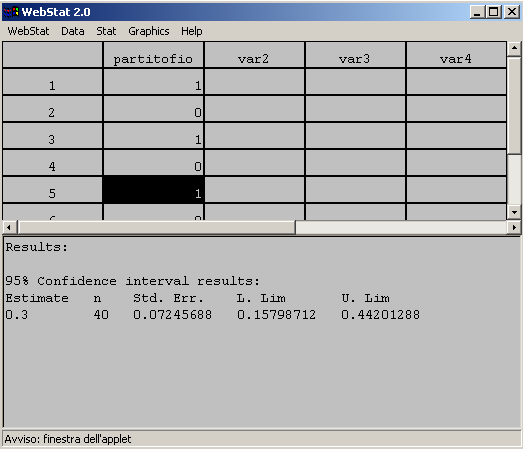
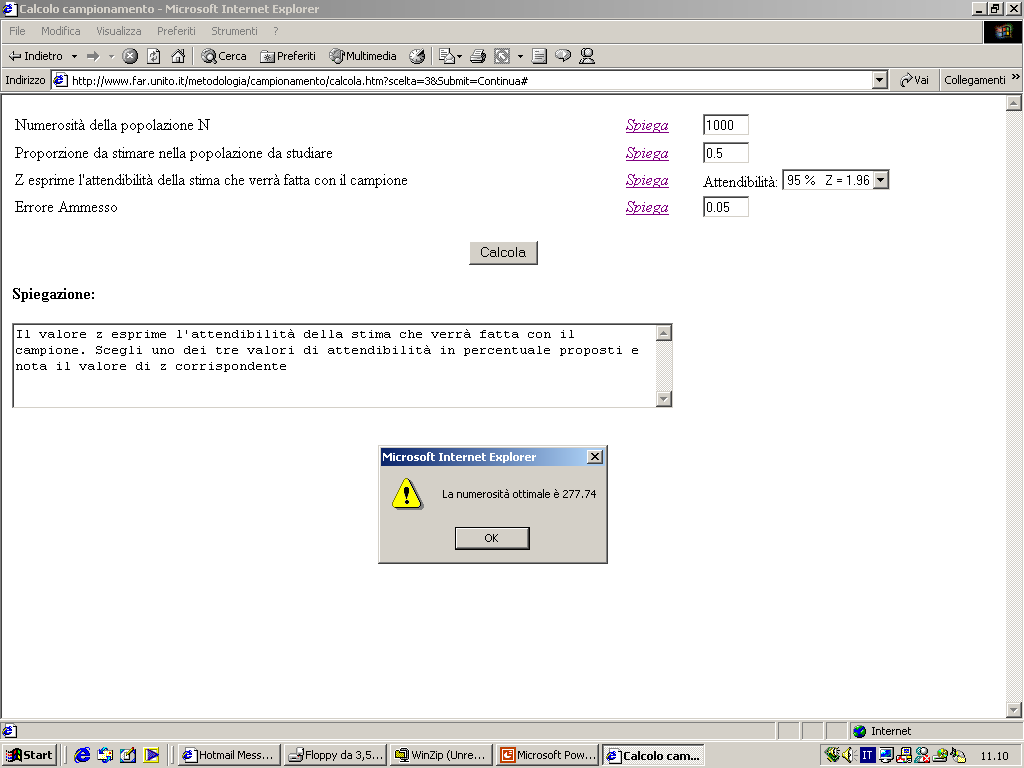
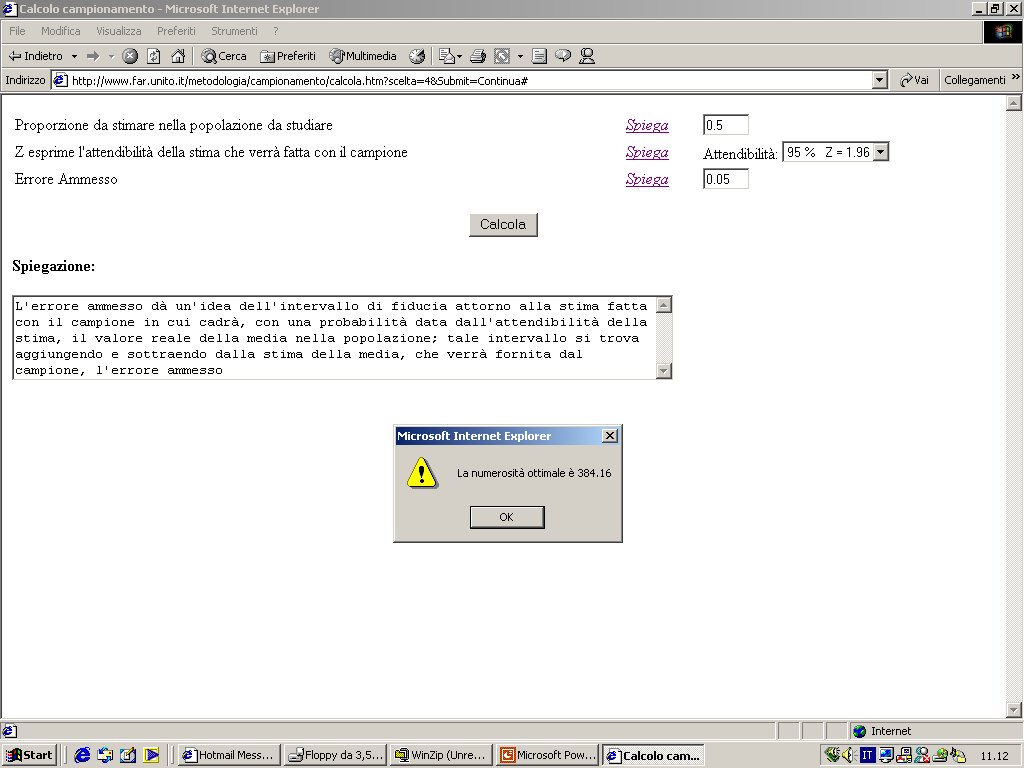
- I limiti di tale intervallo sono:
- Limite inferiore LI = 0.30 -
(1.96)(.072) = 0.16
Limite superiore LS = 0.30 + (1.96)(.072) = 0.44.
- L'intervallo di fiducia sarà quindi:
- Questo significa che (con il 95% di livello di fiducia) la proporzione
di elettori che votano per il Partito della Mela nella popolazione è
compreso tra il 16% e il 44%.
|
|
170
|
|
|
171
|
|
|
172
|
|
|
173
|
|
|
174
|
|
|
175
|
|
|
176
|
|
|
177
|
|
|
178
|
|
|
179
|
|
|
180
|
|
|
181
|
|
|
182
|
|
|
183
|
|
|
184
|
|
|
185
|
|
|
186
|
|
|
187
|
|
|
188
|
|
|
189
|
|
|
190
|
|
|
191
|
|
|
192
|
|
|
193
|
|
|
194
|
|
|
195
|
|
|
196
|
|
|
197
|
|
|
198
|
|
|
199
|
|
|
200
|
|
|
201
|
|
|
202
|
|
|
203
|
|
|
204
|
|
|
205
|
|
|
206
|
|
|
207
|
|
|
208
|
|
|
209
|
|
|
210
|
|
|
211
|
|
|
212
|
|
|
213
|
|
|
214
|
|
|
215
|
|
|
216
|
|
|
217
|
|
|
218
|
|
|
219
|
|

 Note
Note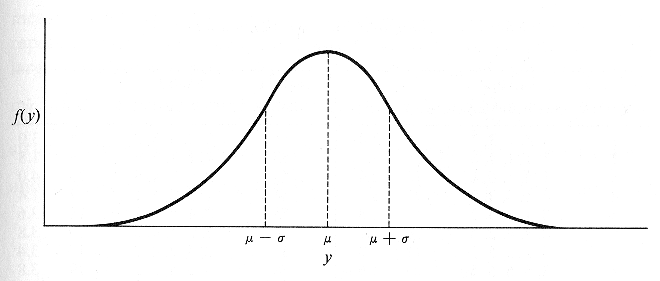{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
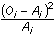{kind=link}
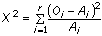{kind=link}
{kind=link}
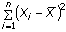{kind=link}
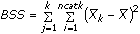{kind=link}
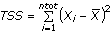{kind=link}
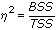{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
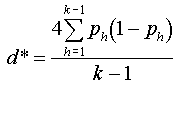{kind=link}
{kind=link}
{kind=link}
{kind=link}
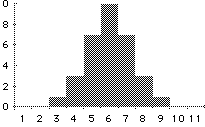{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
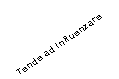{kind=link}
{kind=link}