|
Tabella a doppia entrata (dall’output di Jsstat)
 |
|
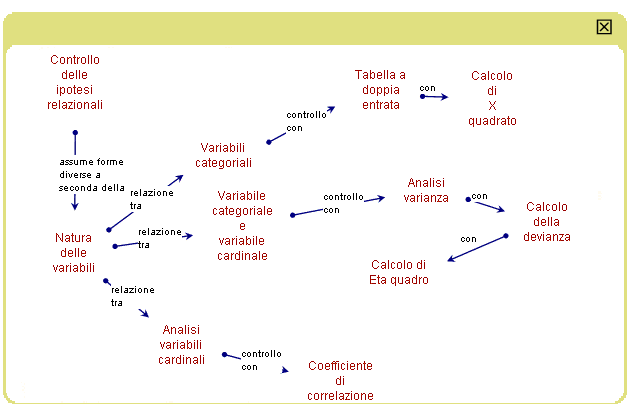
La tabella a doppia entrata riporta la distribuzione
congiunta delle due variabili. I dati del campione ci danno, per
ogni cella: a) la frequenza osservata Oi ossia il numero di casi
che hanno quei dati valori sulle variabili considerate; b) la
frequenza attesa Ai, ossia la frequenza che avremmo osservato
nella cella se la disposizone dei casi nelle celle della tabella
fosse da attribuirsi al caso. E' lecito pensare che questo accada
se non vi è una relazione tra le due variabili. La frequenza
attesa deriva da una semplice proporzione: se non vi è
attrazione tra le modalità delle due variabili il numero
di casi in una cella dovrebbe avere la stessa proporzione rispetto
al suo marginale di riga che ha il suo marginale di colonna rispetto
al totale dei casi, ossia Ai: marginale di riga = marginale di
colonna: totale dei casi da cui deriva che Ai=(marginale di riga
* marginale di colonna)/numero di casi. Quanto più le frequenze
osservate si discostano dalle frequenze attese tanto più
è probabile che vi sia attrazione tra le singole modalità
delle variabili e quindi vi sia una relazione tra le due variabili. |
 |
| Approfondimenti [1] |